Keyboard shortcuts:
N/СпейсNext Slide
PPrevious Slide
OSlides Overview
ctrl+left clickZoom Element
If you want print version => add '
?print-pdf' at the end of slides URL (remove '#' fragment) and then print.
Like: https://progressbg-python-course.github.io/...CourseIntro.html?print-pdf
{kind=link}
Unicode in Python
Created for
Iva E. Popova, 2016-2025,

What encoding means?
- To store anything in a computer, you must first encode it, i.e. convert it to bytes. For example:
- If you want to store music, you must first encode it using MP3, WAV, etc.
- If you want to store a picture, you must first encode it using PNG, JPEG, etc.
- If you want to store text, you must first encode it using ASCII, UTF-8, etc.
Unicode Overview
Unicode Overview
The problem
- In the beginning (1963), there was only ASCII. After that, a bunch of character encodings was used:
- Windows-1252
- KOI8-R
- Windows-1251
- many, many others...
- And the mess begins...
- in KOI8-R, the code '209' == 'я'
- in Windows-1251, the code '209' == 'С'
- in Windows-1252, the code '209' == 'Ñ'
Unicode - The Solution
- Unicode encompasses virtually all characters used widely in computers today.
- As of Unicode version 15.1, there are 149,878 characters with code points, covering 161 modern and historical scripts, as well as multiple symbol sets.
- Even Emojis 😂 !
- Reference: List of Unicode characters @wikipedia
☕
a
ă
я
ছ𝄞
Unicode Encoding
- A Unicode string is a sequence of code points, which are numbers from 0 through 0x10FFFF (1,114,111 decimal)
- This sequence needs to be represented as a set of bytes (1 byte can store values from 0 to (2**8)-1) in memory).
- The rules for translating a Unicode string into a sequence of bytes are called an encoding
- There are various unicode encodings ( UTF-8, UTF-16, UTF-32 and other), but most widely used is UTF-8 which is a variable width character encoding capable of encoding all valid code points in Unicode using one to four bytes
Python’s Unicode Support
Python’s Unicode Support
- From Python3, default string encoding is UTF-8.
- UTF-8 is also the default encoding for Python3 source code.
- Python 3 also supports some Unicode characters in identifiers
низ = "This is a normal Python string :ছ 𝄞 ☕"
print(низ)
# This is a normal Python string :ছ 𝄞 ☕
ord() and chr() functions
ord(char)- return an integer representing the Unicode code point of char given.chr(i)- return the string representing a character whose Unicode code point is the integer i
print( ord('я') )
# 1103
print( chr(1103) )
# я
Unicode symbols in Python strings
- You can use the unicode symbols directly in strings, or, you can enter them using escape sequences
- Example - Various ways to represent symbol: Ѣ
# Unicode symbol in string:
print("Ѣ")
# Using the character name:
print("\N{Cyrillic Capital Letter Yat}")
# Using a 16-bit hex value code point:
print("\u0462")
# Using a 32-bit hex value code point:
print("\U00000462")
Encode-Decode
Encode-Decode
Overview
- Encoding and Decoding refer to the process of converting data between different formats, typically from text to byte representations and vice versa.
- This is important when handling data for various applications, such as reading and writing files or network transmission where data must be in byte format
- Encoding is the process of converting a string (text) into a specific byte format using a certain character encoding, like UTF-8 or ASCII.
- Decoding is the reverse process of encoding, where a byte object is converted back into a string using the same encoding format
Encode-Decode Flow
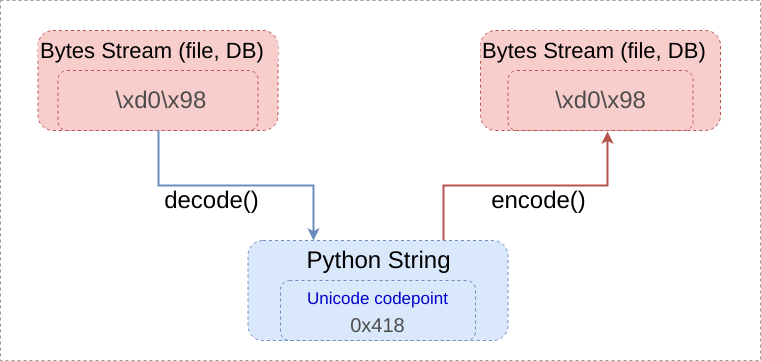
- In byte streams, we have only bytes, but we can interpret them, i.e. to decode, as characters using some character table
encode() - convert String to Bytes
convert String to Bytes
str.encode() - syntax
str.encode(encoding="utf-8", errors="strict")
- Return an encoded version of the string as a bytes object
- Default encoding is 'utf-8'
- List of possible encodings: Standard Encodings
- The default for errors is 'strict', meaning that encoding errors raise a UnicodeError.
- More on str.encode(): str.encode @python3 docs
str.encode() - example
string = "123абв"
bytes_string = string.encode()
print("Byte object:", bytes_string)
print("Type: ",type(bytes_string) )
print("Length:",len(bytes_string) )
#Byte object: b'123\xd0\xb0\xd0\xb1\xd0\xb2'
#Type: <class 'bytes'>
#Length: 9
Note, that the len() of byte object returns the number of bytes, not the number of characters encoded!
UnicodeEncodeError - example
- In next example we try to encode a string using ASCII. Convertion will raise UnicodeEncodeError for non-ASCII characters
text = 'Здравей, свят!'
try:
ascii_encoded = text.encode('ascii')
print("ASCII Encoded:", ascii_encoded)
except UnicodeEncodeError as e:
print("Error:", e)
# Error: 'ascii' codec can't encode characters in position 0-6: ordinal not in range(128)
decode() - convert Bytes to String
convert Bytes to String
bytes.decode() - syntax
bytes.decode(encoding="utf-8", errors="strict")
- Return a string decoded from the given bytes
- Default encoding is 'utf-8'
- List of possible encodings: Standard Encodings
- The default for errors is 'strict', meaning that encoding errors raise a UnicodeError.
- More on bytes.decode(): bytes.decode @python3 docs
bytes.decode() - example
byte_string = b'\xd0\xb0\xd0\xb1\xd0\xb2'
string = byte_string.decode()
print("String object:", string)
print("Type: ",type(string) )
print("String length:",len(string) )
print("Byte_string length:",len(byte_string) )
# String object: абв
# Type: <class 'str'>
# String length: 3
# Byte_string length: 6
The bytes object
The bytes object
Bytes Object
- A bytes object is a built-in data type in Python representing a sequence of bytes.
- Bytes objects are created using the
bytes()constructor or by using a bytes literal prefixed withb(bytes string). - Bytes objects are immutable (cannot be changed after creation).
- They are typically used to store raw binary data, such as images, audio files, or network packets.
- Example:
- More on bytes objects: Bytes objects and Bytearrays
# Define a byte string
byte_string = b'Hello'
print("Byte String:", byte_string)
# Create a bytes object with the same bytes as in byte string above
byte_data = bytes([72, 101, 108, 108, 111])
print("Bytes Object:", byte_data)
# Check if both objects contain the same bytes
if byte_string == byte_data:
print("The byte string and the bytes object contain the same sequence of bytes.")
else:
print("The byte string and the bytes object do not contain the same sequence of bytes.")
# Byte String: b'Hello'
# Bytes Object: b'Hello'
# The byte string and the bytes object contain the same sequence of bytes.
Encode/decode examples and use-cases
Encode/decode examples and use-cases
encode/write examples
- Next two examples achieve a same goal - to save a Python string into text file, encoded as 'cp1251'
- Usually, for such task, you would like to use the open() in text mode with encoding option
- Using
encode()method - Note, that if you open the txt files in VSCode (which by default uses UTF-8), you'll see "����� ���� �����".
- But you can tell (CTRL+SHIFT+P) VSCode to "Change File Encoding"=>"Reopen with Encoding" and select from encoding list "Cyrillic Windows-1251
string = "Петър плет плете"
# open a file for writing in text mode, with encoding="cp1251" "
with open("write_to_cp1251.txt", "w", encoding="cp1251") as fh:
fh.write(string)
string = "Петър плет плете"
# open a file handler for writing in binary mode"
with open("encode_to_cp1251.txt", "w+b") as fh:
bytes_sequence = string.encode(encoding="cp1251")
fh.write(bytes_sequence)
decode/read examples
- Next two examples achieve a same goal - to read from text file, encoded as 'cp1251'
- Usually, for such task, you would like to use the open() in text mode with encoding option
- Using
decode()method
filename = "write_to_cp1251.txt"
# open a file handler for reading in text mode, with encoding="cp1251""
with open(filename, "r", encoding="cp1251") as f:
print(f.read())
# Петър плет плете
filename = "write_to_cp1251.txt"
# open a file handler for reading in binary mode"
with open(filename, "r+b") as f:
bytestring = f.read()
decoded_string = bytestring.decode(encoding="cp1251")
print(decoded_string)
# Петър плет плете
Resources
Resources
Texts
Exercises
Task1: guess_the_quotes
The Task
- Given is next file: quotes.txt, containing quotes in Cyrillic, from a famous writer. But, the file is encoded in KOI8-R
- Write a program:
koi8r_to_utf8.py, which will receive an input file name as argument and will create an UTF encoded file with the same name, but with sufix "_utf8_" added (quotes_utf8_.txt). - Now, you'll be able to open and read the text with your favourite editor
Program usage example
.
├── koi8r_to_utf8.py
└── quotes.txt
$ python koi8r_to_utf8.py quotes.txt
.
├── koi8r_to_utf8.py
├── quotes.txt
└── quotes_utf8_.txt
Make sure, that quotes_utf8_.txt is properly converted and readable!
These slides are based on
customised version of
framework